Reinforcement Learning with Adaptive State Segmentation
in Partially Observable Markov Decision Process
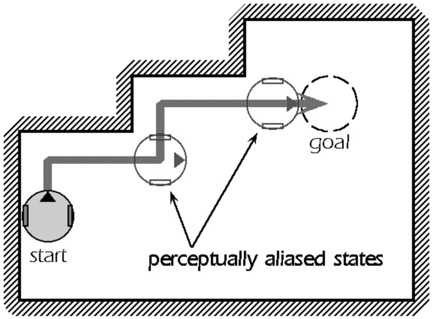
Reinforcement learning is widely noticed as a promising method for robot learning. Reinforcement learning has the following advantages: (1) Behaviors of robot can be acquired only by assigning rewards and punishments, (2) Rewards and punishments can have a delay. However, reinforcement learning also has the following two faults. First, in reinforcement learning, the environment is modeled as Markov Decision Process (MDP). MDP means a decision process where the result of present action depends only on the present state. In robotics, it means that a robot can identify the present state. This is not realistic because, in order to satisfy this assumption, the perception of robot should be a complete one, while the robot can observe the environment partially in general (Fig.1). Secondly, in ordinary reinforcement learning, it is assumed that the states of robots are discretized into finite ones by a designer in advance. However, the descretization of states appropriate for the robot / task / environment is not clear in advance. So the state should be segmented autonomously according to the structure of body of the robot in the course of the task execution.
Recently, the approaches aiming to solve these problems are proposed. Toward the first problem, there are some methods that model the environment as Partially Observable Markov Decision Process (POMDP) and deal with reinforcement learning on POMDP. Toward the second problem, some approaches that autonomously segment robotüfs state-space while learning are proposed. However, these two problems usually exist simultaneously. Hence these problems should be solved simultaneously. This research aims to propose a learning system that solves these problems simultaneously.
The proposed concrete methodology is following. In order to deal with partial observability, we adopt a state representation of decision tree based on the observations and actions in last few steps in order to identify the robotüfs present state according to the history of observations / actions (Fig.2). In the tree structure, each layer corresponds to the observations and actions of n steps ago. States correspond to the leaf nodes. In order to segment states autonomously, the observation space is incrementally segmented by Voronoi hyper-planes based on the acquired observations and rewards at the nodes corresponding to observation.
Keywords: Partially Observable Markov Decision Process, Autonomous State Segmentation, Reinforcement Learning.
Fig.1
Example of POMDP
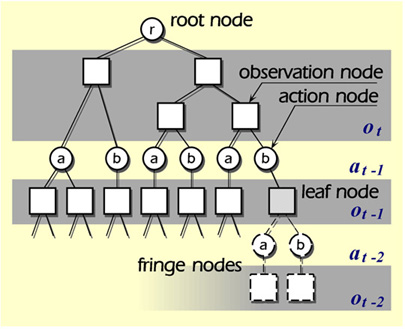
Fig.2
State Representation