部分観測環境下における自律的状態分割に基づく強化学習
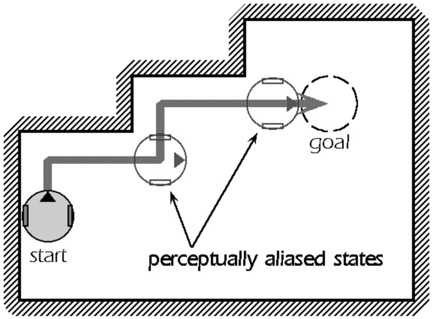
ロボットの行動学習のための有望な手法として,強化学習が注目されている.強化学習の利点として,以下のものがある: (1) 報酬と罰を与えるだけで行動が獲得可能, (2) 遅れのある報酬と罰を手がかりにして,そこへ至る行動系列を獲得可能.しかし,強化学習は以下のような問題点も含んでいる.第一に,環境を Markov 決定過程( MDP: Markov Decision Process )としてモデル化している. MDP とは現在の行動の結果が現在の状態だけに依存するという性質を持つ決定過程を言い,ロボット工学においてはロボットの置かれた現在の状態を一意に決定可能であるという意味を持つ.しかし,このためには完全知覚を前提とせねばならず,現実的ではない( Fig.1 ).第二に,一般的な強化学習では状態があらかじめ設計者により有限数に離散化されているという前提がおかれている.ロボット・タスク・環境に応じた適切な離散化の方法はあらかじめ明らかではなく,タスク実行の過程で,ロボットの身体性に基づいて自律的に状態の離散化が行われなければならない.
近年では,これらの問題点を解決するためのアプローチが提案され始めている.第一の問題に対しては,環境を部分観測 Markov 決定過程( POMDP: Partially Observable Markov Decision Process )としてモデル化し, POMDP 上での強化学習を扱ったいくつかの手法が提案されており,第二の問題に対しては,ロボットの持つ状態空間をロボットの身体性に基づいて自律的に構成しながら学習を行うというアプローチが提案されている.しかし,ロボット工学においては,通常これら二つの問題が同時に存在するため,これらを同時に扱う手法が必要とされている.本研究ではこれら二つの問題を同時に解決する学習システムの提案を目的とする.
具体的な方法論を以下に述べる.部分観測性への対応に対しては,ロボットの過去数ステップの履歴を手がかりにしてロボットの状態を識別するために,過去に得た観測および過去に行った行動に基づく木構造の状態表現を採用する( Fig.2 ).木構造では,各層がn ステップ前の観測及び行動に対応しており,現在の状態に対応するのは葉ノードである.状態の自律的分割に対しては,この木構造中の観測に対応するノードにおいて,過去に得られた観測値とその際に得られた報酬の値に基づき,観測値の空間を Voronoi 超平面により漸次 2 分割することにより,分割を行う.
Keywords
: Partially Observable Markov Decision Process, Autonomous State Segmentation, Reinforcement Learning.参考文献 井上康介 , 太田順 , 千葉龍介 , 小林祐一 , 新井民夫 : “ 部分観測環境下における強化学習による行動獲得 ,” 第 11 回自律分散システム・シンポジウム予稿 , pp.271-274, 1998.
Fig.1
Example of POMDP
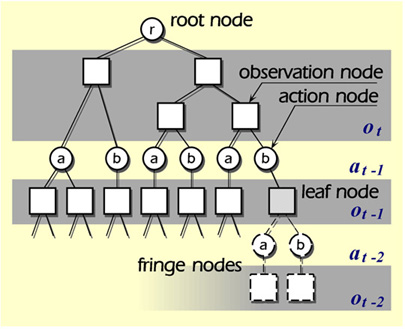
Fig.2
State Representation